The Hidden Corruption Tax of AI Delegation
Frontier LLMs corrupt 25% of what you delegate. The fix isn't going back to writing by hand. It's the same linters and CI we built for humans, finally pointed at the new worker.

Frontier LLMs corrupt 25% of what you delegate to them in long workflows. The new genre of “I went back to writing code by hand” essays says the answer is to fire the LLM. They have the diagnosis wrong. We solved this exact problem for humans twenty years ago, with linters and CI. We just forgot to apply any of it to the new worker.
A new paper from Microsoft Research, LLMs Corrupt Your Documents When You Delegate by Laban, Schnabel and Neville, put a number on something most of us had been seeing for months. Across 52 professional domains, in long delegated workflows, even the frontier (Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4) corrupted an average of 25% of document content by the end of a 20-interaction relay. The average across all 19 models tested was 50%. Errors were sparse but severe. They compounded with document size, turn count, and distractor files in context. Agentic tool use made it worse, not better.
The 25% comes from a backtranslation simulation (forward edit, reverse edit, compare to original), so it’s a proxy for cumulative drift, not a literal claim about your next delegated diff. The point isn’t the exact number. The point is the proxy holds across 19 models, 52 domains, document sizes and turn counts, in the same direction. The shape of the failure is real even when the headline number is conservative.
The honest reaction to that shape isn’t “see, AI is useless.” It’s: of course it drifts, what did you build to catch the wrong slice?
Sparse but severe is the worst kind of bug
If LLM errors were dense and obvious, we would catch them. The whole industry would have rejected vibe coding by now. The paper’s finding is more uncomfortable: the model is right most of the time, then quietly wrong about one critical thing, then right again. The result reads correctly. It compiles. It even ships.
This is the worst possible error profile for human reviewers. Rare anomalies in a sea of normal-looking output are exactly what humans miss, every time, in every field that has bothered to study it. The LLM accidentally built an attention trap.
It also gets worse with size. Bigger document, longer interaction, more distractor files in the context: degradation compounds. So the more useful you try to make delegation (“rewrite the whole spec” instead of “fix this one line”), the worse the corruption gets. The delegation interface rewards exactly the workflow that fails hardest.
Going back to writing by hand is firing the junior
Every few weeks now, a senior engineer publishes the same essay. I quit the AI assistants. I am writing code by hand again. I am faster, the bugs are gone, my brain is back. Each one gets three hundred HN comments saying “finally, someone said it.”
I read those posts and I see the same mistake a stretched manager makes about a struggling junior: I should just write the code myself, they suck. No. They don’t suck. You skipped onboarding. You didn’t give them a feedback loop. You didn’t pair-review their first ten PRs. You set them up to fail, then concluded that hiring juniors is broken.
LLMs are the same shape of problem. We have been onboarding humans into software projects for decades, and we long ago stopped trusting them blindly. We require their code to compile. We require it to pass a linter. We make them write tests. We force it through type checkers, static analysis, security scanners, dependency auditors. We don’t do this because junior engineers are bad people. We do this because anyone producing code at speed quietly breaks things, and the deterministic harness catches it before production does. (As I wrote a while back, AI won’t kill juniors, it’ll expose stagnant seniors: same problem, same diagnostic mistake.)
Now the industry has hired the most prolific junior in history, and most teams forgot to point any of that harness at its output.
We already built the fix. It’s called a linter.
The first thing you do when you start a new repository is not turn on Ruff, ESLint, Biome, cargo clippy, mypy, gosec, semgrep. It should be. It almost never is. Most new repos start out with a default GitHub Action template at best. Rarely a security linter. Almost never a custom rule for the smells that actually bite this codebase. And those are the projects humans are writing.
Then we plug an LLM into the same unguarded repo and act surprised when the same failure mode shows up in the diff.
Linters are the cheapest deterministic check we have. They exist precisely because we already learned the lesson the DELEGATE-52 paper had to re-prove with a small mountain of inference: confident producers of code make sparse but severe errors at scale. That’s the entire reason the toolchain exists. Pointing it at an LLM doesn’t require a research breakthrough. It requires turning on the thing we built for humans and forgot to wire up.
The corruption tax compounds because we removed the harness when we changed the worker. Same mistake we make when we send a junior into a repo with no CI and then blame the junior.
The obvious objection: linters catch syntactic bugs, not semantic ones. A regex flipped from ^foo$ to ^foo passes every static check. So does a dosage that went from 5mg to 50mg, an off-by-one in a business rule, a swapped argument when both types match. That is correct. It’s also exactly why the current agentic coding tools (Cursor, Claude Code, Aider) run linters and unit tests inside their loop, and the paper’s degradation numbers are still collected on top of harnesses like that. A single linter pass isn’t the harness. That’s the whole point. We also built property-based testing, fuzzing, golden-file diffs, contract tests, snapshot review, and the boring discipline of two humans signing off on a change. The harness is layered. The frontier LLMs are sparse-but-severe at every layer of it, which is what the paper actually shows. You don’t pick one tool; you stack them, because every layer catches a different class of wrong.

The paper itself makes this point in passing: out of 52 domains tested, Python was the only one where most LLMs reached “ready” status. The paper credits “verifiable rewards”, the fact that code can be checked deterministically. That is just another way of saying Python comes with a harness, the one programmers built precisely because any writer, junior or LLM, will quietly drift unless something deterministic catches them. Crystallography, music notation and accounting ledgers have spell-check at best. The domain with the densest harness is the domain where delegation actually works. That is not a coincidence.

In every other domain, DELEGATE-52’s 25% becomes a corrupted file you ship and nobody catches, because there’s no automated reader behind the human one. If you delegate to an LLM in a domain without deterministic checks, you are the harness. Act like it.
The interface helps too, but it’s not the whole game
There’s still a real interface problem on top of this. The dominant UX for delegated work is “here is the doc, do your thing”: the model returns a new version, you skim it, you ship it. Implicit acceptance, hidden diff. That is the worst possible UI for a tool whose failure mode is silent corruption.
Cursor, Claude Code and Aider all show diffs. Real ones. But “show a diff” is not “force a diff”. You can still click accept-all on a thousand-line refactor at three in the morning. The fix is making review the default path, not an option: forced span-level acceptance, drift indicators across long sessions, distractor-file warnings, visible quality-loss curves as the doc grows. As I argued in AI is a human interface nightmare, the pattern is depressingly consistent. Decent models surrounded by terrible UI for catching when they’re wrong.
These are product problems, not research problems. They are exactly the same guardrail work we did for code review tooling over the last fifteen years. Same job, new worker.
You have to read what you delegate. You also have to lint it.
Until both the interface and the harness catch up, the defenses are boring. Diff what you delegated. Re-read every line the model touched. Run the linter. Run the tests. Run the security scanner. If you don’t have time to do that, you didn’t have time to delegate the task in the first place. You were borrowing against your future self, and a slice of the document is already gone.
I have shipped features at Mergify where I wrote maybe five percent of the lines myself and Claude wrote the other ninety-five. It worked. The reason it worked is not that I read every line with a microscope. It’s that Biome, mypy, our test suite, and a Copilot review pass read the diff before I did. The harness was the reviewer I didn’t run. The corruption tax was paid quietly in the background, and the linters caught what mattered. Take the harness away, and that same PR is a future incident.
The AI free lunch was about who pays for the compute. The corruption tax is about who pays for the silence. Both bills come due. Both are starting to.
The answer to both, weirdly, is the same boring thing: build the safety net you always should have had. The LLM didn’t change that. It just punished the teams that never bothered.
Related posts
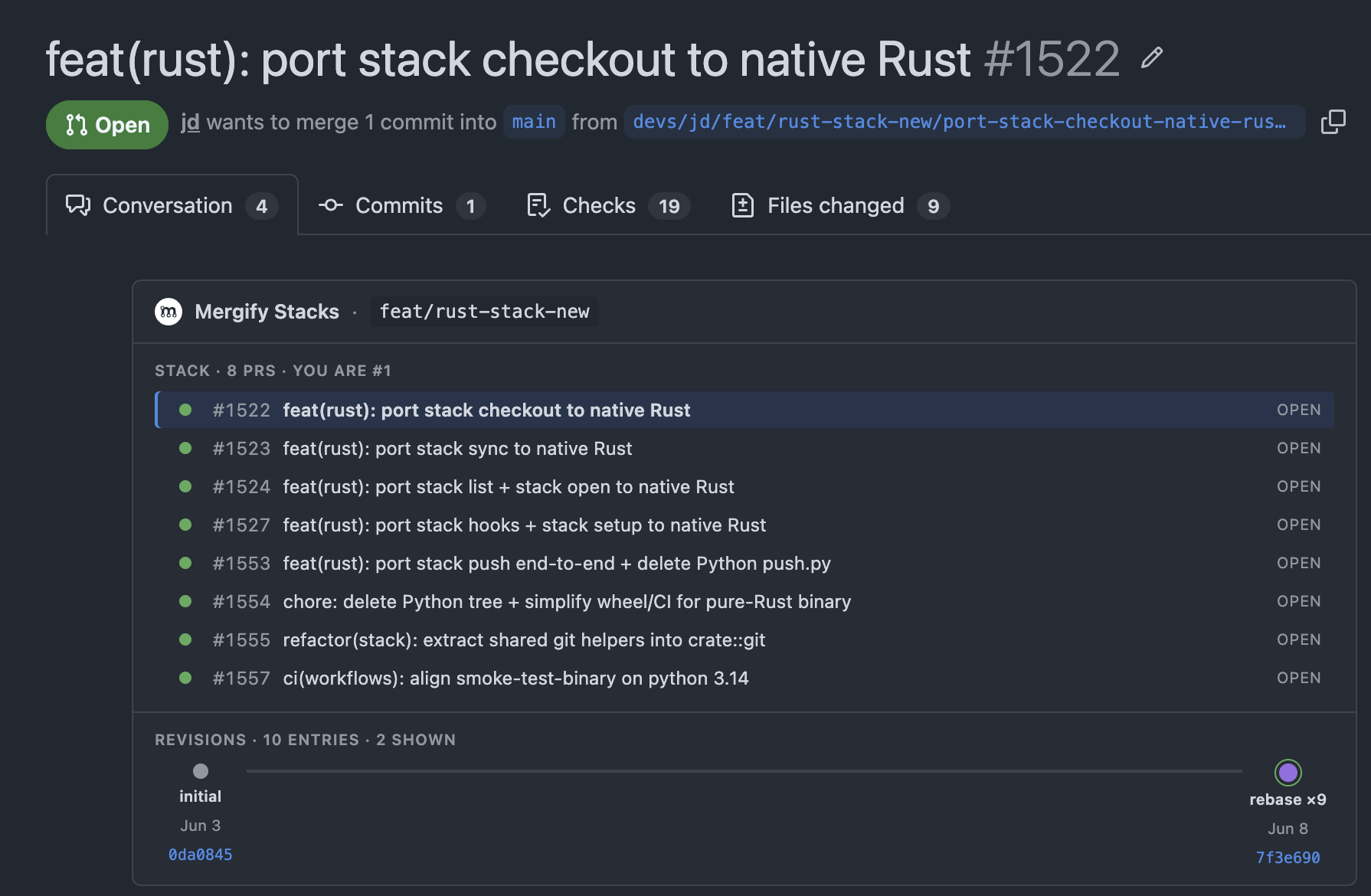
I Shipped a Rust Binary. I Can't Write Rust.
A rewrite used to be career suicide. Porting our CLI to Rust took a month of review and a model that knew the language better than I ever will.
Read more →
Your CI Pipeline Wasn't Built for This
AI writes code 10x faster than humans. CI still runs at the same speed, fails for the same flaky reasons, and costs more every month. Something has to give.
Read more →