I Shipped a Rust Binary. I Can't Write Rust.
A rewrite used to be career suicide. Porting our CLI to Rust took a month of review and a model that knew the language better than I ever will.
I started shipping a Rust binary last month. I can’t write Rust.
I can squint at it and roughly follow what’s happening. Past that I’m lost: the borrow checker yells at me and I take its word for it. Sit me in front of an empty main.rs and ask me to build something real, and you’d be waiting a very long time. Yet the Mergify CLI is becoming a single native Rust binary, one command at a time, and the Rust that’s already in production was mostly written by a model that knows the language far better than I do.
A year ago that sentence would have been a lie. Today it’s just how the work got done.
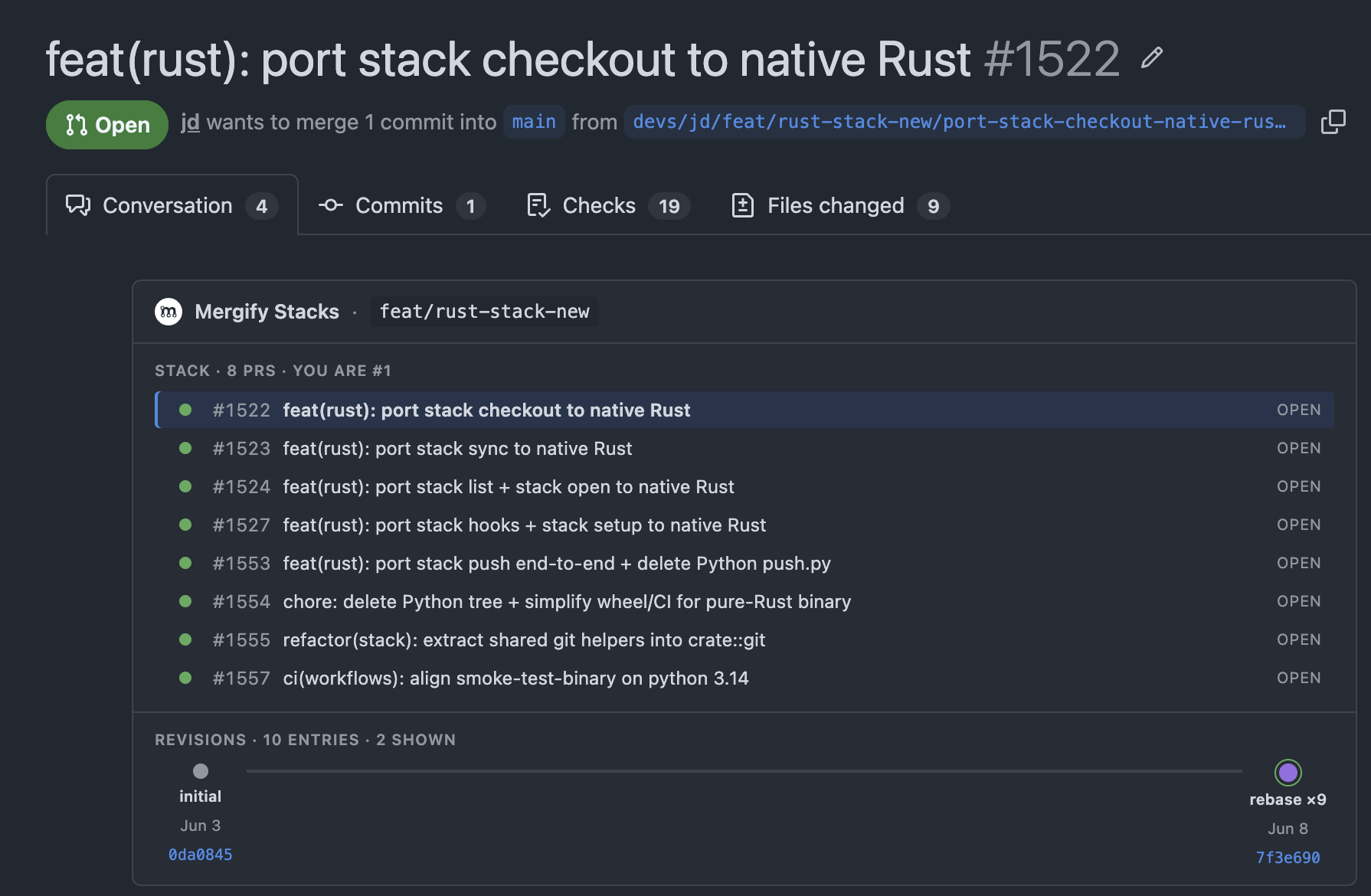
That’s just the tail of the stack: each command ported in its own pull request, right down to the one that deletes the Python tree for good. The port has run to more than forty merged PRs so far, one command at a time. That’s the entire trick.
Why we touched it at all
The CLI was Python, shipped the usual way: pip, then uv tool install. Python isn’t hard to ship. But “ships” and “ships everywhere, fast, as one file” are different bars. We were fighting interpreter assumptions, a clumsy Windows install story, and a startup cost you feel on every invocation of a tool people run dozens of times a day.
A single native binary fixes most of that. It starts instantly and it runs the same on every machine without a runtime to drag along.
But the binary wasn’t the real reason. The real reason is reuse. We want the guts of the CLI, the stack logic, the git plumbing, the GitHub glue, to become a shared native core we can call from other places: a Python library through PyO3, a TypeScript binding later, and whatever else needs it. A CLI today, a library tomorrow, one implementation underneath. Python could never be that common ground (not easily): you’d be shipping an interpreter into every consumer. A native language can.
Why Rust and not, say, Go? Partly the reuse story is cleaner from Python (PyO3 beats wrangling cgo). Partly the team wanted Rust, and a team that’s excited about the language writes better code in it. I won’t pretend it was a pure spreadsheet decision.
”But you should never rewrite”
The instinct, the moment you say “rewrite,” is to quote Joel Spolsky. In 2000 he wrote Things You Should Never Do, and the never is rewriting your software from scratch. He’s right. He’s still right.
But read what he actually warned against. Throwing away working code is throwing away every bug someone hit in production, every weird edge case a customer found, every fix that looks pointless until you remember why it’s there. Knowledge accumulates in code as scar tissue, and a from-scratch rewrite cuts it all out and dares you to grow it back.
We didn’t do that. We didn’t start from scratch. We ported.
A port is a translation, not a reinvention. Same behavior, same edge cases, same tests, different language. You don’t move it line by line, the two languages disagree about almost everything, but you’re re-expressing decisions that were already made instead of making them fresh. The scar tissue lives in the behavior and the tests, and that comes along for the ride. That distinction is the whole game. A from-scratch rewrite is still an excellent way to kill your project. A port has quietly become cheap to write.
“Don’t rewrite” and “don’t port” were never the same rule. We just couldn’t tell them apart when both cost a year.
How we did it without blowing a leg off
The tempting version is obvious: hand the whole tree to an LLM, say “make this Rust,” and merge the enormous green PR. When Bun did exactly that, the result was a single pull request north of a million lines, and it’s easy to dunk on. I won’t. At that code size, porting command by command the way we did would have taken them the better part of a year, and nobody signs up to run a migration that long. They jumped and crossed their fingers because the careful path wasn’t really a path, it was a sentence.
But the gamble is real, and worth naming. A million lines in one PR is not something a human reviews, green checks or not. The tests can pass and you still have no idea what you merged. That’s not merging code, it’s merging hope. A one-shot port stops being a port and turns back into a rewrite, with all of Joel’s problems plus a model’s confident mistakes. I dug into why on the Mergify blog.
We never had to make that bet. Our surface was small enough that the careful path cost weeks, not years, so we took it. It looks slow. It’s actually fast.
Command by command. mergify stack push first, then fixup, then note, then drop, each one its own change. Never more than one command in flight.
A shim between Python and Rust, so the tool was always shippable. Mid-migration, half the commands ran on Rust and half still ran on Python, and the user couldn’t tell. No big-bang cutover, no branch that lives for three months and rots. The whole architecture is one decision. Route to the native implementation if it exists, fall back to the Python one if it doesn’t, same behavior either way:

Tests as guardrails. Every command the model ported got unit, functional, and smoke tests around it. The model wrote those too, and yes, that’s a loop worth worrying about: a model grading its own homework. What breaks the loop is that we weren’t inventing correct behavior, we were copying it. The Python CLI was right there, in production, defining exactly what each command should do, and because the shim kept both alive we could run the two side by side and compare. The model gets to write the Rust and the tests. It doesn’t get to decide what correct means. The old code already did, and that’s why I can trust code written in a language I can’t.
Small, reviewable steps. We split the whole thing into stacked pull requests so each port was a few hundred lines, reviewable in one sitting, merged on its own. The stack is what kept a month-long migration from ever feeling like a month-long migration.
The bottleneck moved
Here’s the number that surprised me. The actual code generation? You could do this in a few days. Maybe one, if you did nothing else and didn’t stop to review.
It took us three weeks to a month. Not because the writing was slow, but because reviewing is the bottleneck now. Reading every diff, in a language I’m still learning, while also running a company. The model produced faster than we could absorb.
That’s the real shape of AI-assisted engineering right now, and it’s the same lesson I keep landing on: writing got cheap, reviewing didn’t. The cost of software moved from your fingers to your eyes. I’ve written before about the corruption tax you pay when you delegate to a model and don’t read the result, and this is the same coin, flipped to the happy side. The guardrails and the reading are not overhead. They are the work now.
What I gave up
I don’t fully know the code we’re shipping. Some of it is probably not idiomatic Rust. There are likely allocations a real Rust programmer would avoid and patterns they’d wince at. The model is a better Rust programmer than I am, and for a CLI where correctness matters more than elegance and the tests cover the behavior, I’m at peace with that.
I’m also clear about why this worked, because it tells you when it won’t. It’s a CLI. The behavior is well defined. The test coverage was good before we started. I would not do this blind on a system I couldn’t test thoroughly, or one where “probably correct” isn’t good enough. The method isn’t magic. It leans entirely on the fact that we could prove the new code behaved like the old code.
The lesson isn’t “rewrite everything in Rust.” It’s that the calculus changed. The reason you never rewrote was that rewriting cost more than it returned. Porting, with a model that writes the language and tests pinned to behavior you already trust, slipped under that line while everyone was still quoting an essay from 2000. The news isn’t that an AI wrote Rust. It’s that porting, always the safer half of Spolsky’s rule, finally got cheap enough to just do.
I still can’t write Rust. Turns out I didn’t need to.
Related posts

The Hidden Corruption Tax of AI Delegation
Frontier LLMs corrupt 25% of what you delegate. The fix isn't going back to writing by hand. It's the same linters and CI we built for humans, finally pointed at the new worker.
Read more →
Merge Queues Were Built for Humans. Agents Don't Wait.
Mitchell Hashimoto says merge queues fall apart under AI agents. I run a merge-queue company, and he's half right. The queue isn't the thing that breaks.
Read more →