Open Source Is Getting Used to Death
AI broke the implicit deal that sustained open source for 30 years. Usage is up. Engagement is gone. The economics don't work anymore.
Tailwind CSS is more popular than ever. Downloads keep climbing. Developers love it. AI coding assistants recommend it constantly.
Its creator, Adam Wathan, says documentation traffic is down 40% and revenue has dropped close to 80%. He laid off 75% of the team last month.
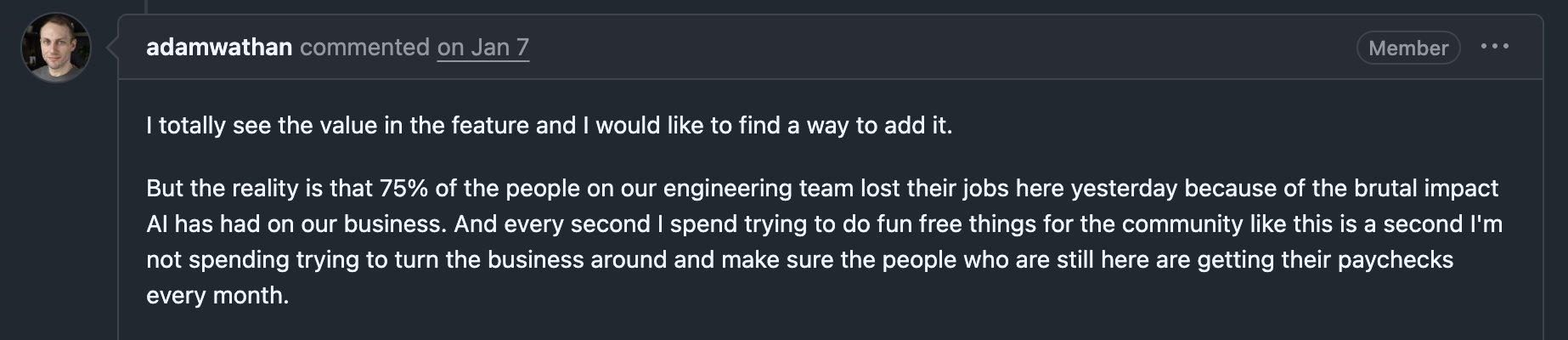
That’s the state of open source in 2026. More usage, less everything else.
The deal nobody signed
Open source always ran on an implicit deal: I share my code, you engage with it. You read the docs, file bugs, sponsor the project, contribute patches, argue about API design. That engagement was the currency that kept the ecosystem alive.
The deal was already fraying. Nadia Eghbal documented this in Working in Public back in 2020: the ratio of consumers to contributors was already thousands to one. Most users never filed a bug, never sponsored anything, never showed up. Maintainers were burning out long before AI arrived.
But AI didn’t just accelerate the decline. It changed the structure.
When Claude writes your Tailwind classes, you never visit the docs. When Copilot autocompletes your curl flags, you never read the man page. When an AI agent assembles your project from a dozen open source libraries, none of those maintainers see a download page visit, a GitHub star, or a support ticket.
The code still flows. The engagement doesn’t.

Two channels, one winner
Koren, Békés, Hinz, and Lohmann lay this out in “Vibe Coding Kills Open Source”, a paper that models two competing forces. AI makes it cheaper to build software — more projects, better code, the flywheel that grew open source for 30 years spins faster. But AI also means users interact with open source through a proxy. They get the value and skip the engagement. Maintainers lose the revenue, reputation, and feedback that justified sharing code.
In the short term, both forces are at work and the good one wins. Long-term, diversion dominates. The flywheel starts running in reverse.
For 30 years, the cycle looked like this: a maintainer shares a library. Developers use it, read the docs, file bugs, sponsor it. The maintainer gets revenue, reputation, and feedback — keeps improving. More developers adopt it. The cycle reinforces itself.

The virtuous cycle that sustained open source for 30 years
Now the loop runs in reverse. A maintainer shares a library. AI agents use it, but users never visit the docs, never file issues, never sponsor the project. Revenue drops. The maintainer burns out and stops maintaining. Developers who need that functionality ask an AI to build it from scratch. That generated code never gets shared back — why would it? And the next maintainer looking at the economics thinks: why bother sharing mine?

The same loop — until it isn’t
Each turn of the cycle is rational. No one’s doing anything wrong. But the collective result is an ecosystem consuming itself.
The data is already there. Stack Overflow lost 25% of its activity within six months of ChatGPT launching — and yes, SO was already declining, but AI cratered the curve. The curl maintainer reports that 20% of security vulnerability reports are now AI-generated garbage. Downloads go up. Everything that matters goes down.
The economics of extraction
When cloud providers started offering open source as a service (the “AWS problem”), maintainers at least knew who was extracting value. You could negotiate. You could change your license. You could build a competing hosted product. You could fight it.
AI extraction is painless — and that’s what makes it lethal. Nobody feels like they’re taking anything. A developer asks Claude a question, gets working code, ships it. The value flows out of open source into training data, into autocomplete suggestions, into vibe-coded projects — and nobody involved ever knows your name. It’s not theft. It’s evaporation.
The paper puts numbers to it: to sustain open source at current levels, you’d need each user to pay roughly what they pay now. But the whole point of AI-mediated usage is that per-user engagement drops to near zero. The math doesn’t work.
What the economists miss
The paper leaves out the part where developers do things because they want to, not because they get paid. It acknowledges this blind spot.
I’ve spent over 20 years in open source — Debian, awesome window manager, GNU Emacs, OpenStack, Mergify — and the economics were never the whole story. A lot of open source ran on ego. And I mean that as a compliment.
You started a project because you were proud of what you built. You maintained it because people used it and told you it was good. You contributed to someone else’s project because it felt meaningful to be part of something bigger. The reputation, the GitHub profile, the conference talks — that was the fuel.
AI erodes that too. When your library is consumed by a model that never credits you, the ego fuel dries up. Nobody’s filing issues saying “great work on this API.” Nobody’s writing blog posts about your clever design decisions. Your code is in millions of projects and you’ll never know.
Michael Still maintained pngtools for 25 years and recently admitted he “can’t really explain what I got in return apart from the occasional dopamine hit.” That’s not bitterness — it’s an honest accounting of what happens when the feedback loop never closes.
The rebuild reflex
Anthropic built a C compiler with Claude. OpenAI built a web browser. This is what happens when development costs collapse.
The obvious objection: generating code isn’t maintaining code. curl works because of 20 years of edge cases, security patches, and platform quirks. You can’t generate that in a weekend. True — but the line between “writing” code and “maintaining” code is blurrier than it looks. Every line you write immediately becomes maintenance. AI doesn’t just generate the first draft — it fixes the bugs, handles the edge cases, iterates on the patches. The entire lifecycle gets cheaper, not just the initial build.
Five years ago, nobody in their right mind would build their own HTTP server, their own date parsing library, their own compression algorithm. You used the shared one because the alternative was insane.
The alternative is no longer insane. It might be a weekend project.
Where this leaves us
Some of this is happening right now. The Tailwind numbers are a Q4 report. Stack Overflow’s decline is measured. The curl maintainer is drowning in AI-generated noise today. Some of it is projection — I’m betting that the diversion effect gets stronger, not weaker, as AI gets better. I could be wrong. But the trend lines all point the same way.
“But AI also contributes!” Sure. Agents file PRs, generate docs, triage issues. That helps with the mechanical work. It doesn’t replace the human who cared enough to read your code and tell you it mattered. The engagement that sustained open source was never about the pull requests — it was about the people behind them.
Open source isn’t dying because people stopped caring. It’s dying because AI lets people extract all the value without returning any of it. The code flows through models, through agents, through autocomplete — and none of it flows back.
The question isn’t whether this is happening. It’s what comes next.
Related posts

How Much Of A Library Do You Actually Use?
Armin Ronacher's 'Build It Yourself' got reposted after the npm attacks. The advice is right. The hard part is the question nobody quite answers: which dependencies do you actually use?
Read more →
GitHub Is Thinking About Killing Pull Requests
Code generation got cheap. Review didn't. That asymmetry is destroying open source faster than any AI policy can fix.
Read more →