How Entire Works Under the Hood
I dug into Entire's open source Checkpoints CLI. It's a clever abuse of git internals — shadow branches, orphan metadata, and a session state machine. Here's how it works.
In part 1, I covered why Entire raised $60M and what problem they’re solving. Now let’s look at the actual code.
I pointed Claude Code at Entire’s open source CLI and asked it to explain how things work. The architecture is more interesting than I expected — they’ve essentially built a session-aware metadata layer on top of git using nothing but git’s own primitives.
The Big Picture
Entire hooks into two things: your AI agent (Claude Code, Gemini CLI) and git itself. The agent hooks capture what’s happening during a session. The git hooks capture what the developer commits.
Agent hooks (Claude Code) Git hooks
SessionStart prepare-commit-msg
UserPromptSubmit post-commit
Stop pre-push
PreToolUse / PostToolUse
│ │
└──────────┬───────────────────┘
│
┌───────▼────────┐
│ Strategy │
│ │
│ SaveChanges() │
│ Rewind() │
│ Condense() │
└───────┬────────┘
│
┌──────────┴──────────┐
│ │
Shadow branches Metadata branch
(local, temp) (shared, permanent)
entire/<hash> entire/checkpoints/v1How Agent Hooks Get Installed
Running entire enable writes hook entries into .claude/settings.json. Seven hooks, covering the full session lifecycle:
- SessionStart/SessionEnd — track session boundaries
- UserPromptSubmit — fires before the agent starts working (captures human edits)
- Stop — fires after the agent finishes a turn (triggers checkpoint save)
- PreToolUse/PostToolUse[Task] — track subagent spawning
- PostToolUse[TodoWrite] — capture task state
Each hook is just a shell command: entire hooks claude-code stop. The CLI parses the agent’s transcript to extract everything it needs.
The Transcript Is the Source of Truth
This is the key insight. When the Stop hook fires, Claude Code passes two things via stdin: a session_id and a transcript_path. That transcript — the JSONL file where Claude logs every message, tool call, and response — is the single source of truth.
The CLI mines it for:
- Modified files — scans for
tool_useblocks where the tool isWrite,Edit, etc., and extracts thefile_path - User prompts — finds
type: "user"entries - Token usage — sums
input_tokens,output_tokensfrom response metadata - Summary — grabs the last assistant message
No magic, no APIs. It just reads the same JSONL file that Claude Code writes to disk.
Shadow Branches: Snapshots Without Commits
Here’s where it gets clever. When the agent finishes a turn, Entire needs to save a snapshot of the working tree. But it can’t commit to your branch — that would mess up your history.
So it creates shadow branches: refs like entire/2b4c177-a5e3f2 that live in your local repo but never touch your working branch.
The name encodes two things:
2b4c177— first 7 chars of HEAD when the session starteda5e3f2— hash of the worktree ID (to supportgit worktree)
The snapshot is built entirely in memory using go-git’s plumbing APIs:
- Take HEAD’s tree (the full repo structure)
- Apply the agent’s changes (add/remove/modify blobs)
- Attach the metadata directory (
.entire/metadata/<session-id>/) - Create a commit on the shadow branch
No checkout, no stash, no visible side effects. The user and agent don’t even know it happened.
Deduplication is automatic: if the tree hash matches the previous checkpoint, it skips the commit. Git’s content-addressable storage means identical files share blobs across checkpoints.
The Condensation Model
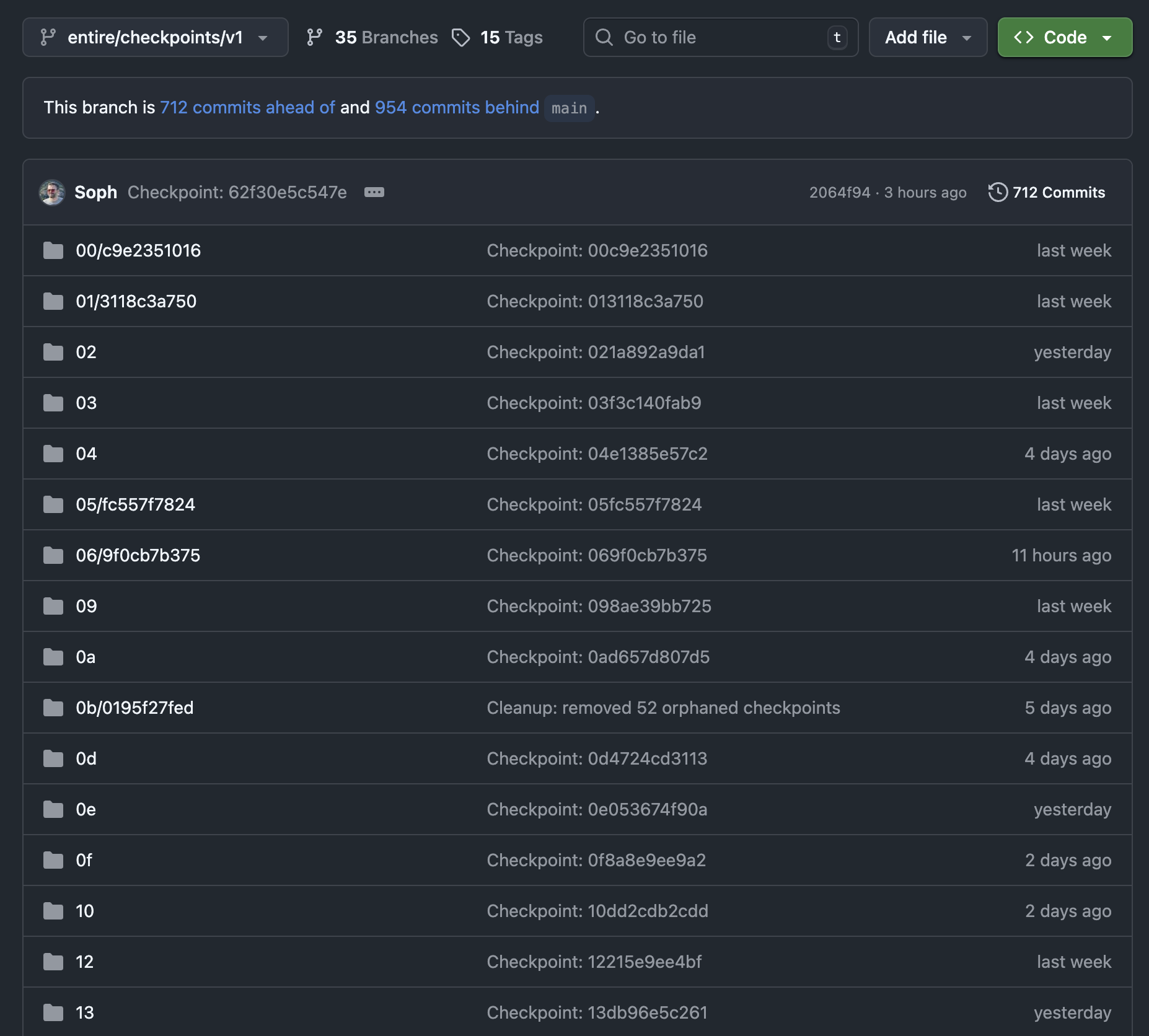
Shadow branches are local scratch space. The real metadata lives on entire/checkpoints/v1 — an orphan branch (no common ancestor with your code) that’s pushed alongside your regular branches.
The flow:
- Agent works → checkpoints saved on shadow branch (local)
- You commit →
post-commithook fires prepare-commit-msgadds a trailer:Entire-Checkpoint: a3b2c4d5e6f7- Shadow branch data gets condensed — copied into the metadata branch
- Shadow branch gets cleaned up
The checkpoint ID (a3b2c4d5e6f7) is 6 random bytes, not a git SHA. It’s sharded into a directory path on the metadata branch:
entire/checkpoints/v1 (orphan branch)
└── a3/b2c4d5e6f7/
├── metadata.json # summary, attribution, token usage
├── 0/
│ ├── full.jsonl # complete session transcript
│ ├── prompt.txt # user prompts
│ └── context.md # generated context
└── 1/ # additional sessions if anyThat one-line trailer in your commit — Entire-Checkpoint: a3b2c4d5e6f7 — is the bidirectional link. From the commit you find metadata via the sharded path. From the metadata you find the commit by searching for the trailer.
Attribution: Who Wrote What?
This is the piece that matters for engineering leads. Entire tracks line-level code attribution: what percentage was agent-written vs. human-written.
The trick is the UserPromptSubmit hook. Every time you type a new prompt — before the agent starts working — the CLI snapshots the worktree diff against the last checkpoint. This captures exactly what you changed between agent turns.
By commit time, it has:
- Agent lines: changes from the last checkpoint’s tree
- Human added: lines you added between prompts
- Human modified: lines you edited in agent-written code
- Agent percentage: the ratio
The result is stored in initial_attribution in the metadata:
{
"agent_lines": 150,
"human_added": 25,
"human_modified": 10,
"agent_percentage": 85.7
}It even uses a LIFO heuristic for self-modifications — if you add lines then remove lines from the same file, it assumes you’re removing your own first, not penalizing the agent’s contribution.
Multi-Developer: Conflict-Free by Design
The metadata branch gets pushed during git push (via the pre-push hook). Multiple developers push to the same entire/checkpoints/v1 branch.
This works because checkpoint IDs are random — two developers will essentially never produce the same 12-hex-char ID. Merging is just a tree union: flatten both trees, combine entries, done. No merge conflicts possible.
If a normal push fails (non-fast-forward), the CLI fetches the remote, merges trees, creates a merge commit, and retries.
What’s Missing
The architecture is solid engineering, but a few things stood out:
Transcript privacy. Session transcripts (full agent conversations) get pushed to a branch anyone with repo access can read. For private repos, maybe fine. For orgs with varying access levels — that’s a problem.
Squash merges break links. If a PR with 5 commits (each with Entire-Checkpoint trailers) gets squash-merged, those trailers disappear. The metadata exists but the bidirectional link from the merged commit is broken.
The metadata branch grows forever. Every session from every developer, including abandoned PRs and throwaway experiments, accumulates on entire/checkpoints/v1. There’s an entire clean command for local shadow branches, but no retention policy for the permanent metadata. For a large team over months, that’ll bloat.
No PR linkage. The branch name is stored, but there’s no PR number or URL. You can’t easily ask “show me all sessions related to PR #42.”
The Smart Parts
What I genuinely admire:
Git as a free database. Shadow branches store full repo snapshots, but git’s content-addressable storage means only changed blobs cost anything. You get atomic snapshots, deduplication, and transport for free.
In-memory tree building. Checkpoints are created through go-git plumbing APIs — no worktree checkout, no stash, nothing visible. Zero disruption to the developer’s flow.
Attribution at prompt boundaries. Capturing human edits before the agent contaminates the worktree is the cleanest measurement point possible.
Shadow branch migration. If you rebase or pull (HEAD changes), the shadow branch name automatically updates. Your session continues seamlessly. This handles a common workflow that would otherwise silently break.
So What?
Entire doesn’t solve a burning problem today. Most of us are fine with agent-written code landing in our repos without detailed provenance. But the trajectory is clear: as agents write more code, the audit trail becomes essential.
The approach of storing session context alongside code in git — rather than in a separate system — is the right architectural bet. Git is already where your code lives, where your CI runs, where your reviews happen. Adding a metadata layer inside git itself (instead of a SaaS dashboard somewhere) means the context travels with the code.
Whether Entire is the company that turns this into a platform worth $300M is above my pay grade. But the engineering is genuine, the problem is real, and the timing feels right.
I’ll be watching.
Related posts
Agent-Written Code Needs More Than Git
The former GitHub CEO just raised $60M to rebuild developer tooling for the agentic era. He might be right that git needs a rethink — I've been hacking around the same problems.
Read more →
Merge Queues Were Built for Humans. Agents Don't Wait.
Mitchell Hashimoto says merge queues fall apart under AI agents. I run a merge-queue company, and he's half right. The queue isn't the thing that breaks.
Read more →